클러스터링
학습 목표
이 레시피를 완료하면 다음을 할 수 있습니다:
- K-Means 클러스터링 수행
- 최적 클러스터 수 결정 (Elbow, Silhouette)
- RFM 기반 고객 세그멘테이션
- 클러스터 프로파일링 및 시각화
1. RFM 분석이란?
이론
RFM은 고객의 가치를 평가하는 마케팅 분석 기법입니다.
- R (Recency): 최근성 - 마지막 구매가 얼마나 최근인가?
- F (Frequency): 빈도 - 얼마나 자주 구매하는가?
- M (Monetary): 금액 - 총 얼마나 지출했는가?
비즈니스 활용
| 세그먼트 | 특징 | 마케팅 전략 |
|---|---|---|
| Champions | 최근 구매, 자주, 많이 | VIP 혜택, 신제품 우선 안내 |
| Loyal | 자주 구매 | 로열티 프로그램, 업셀링 |
| New | 최근 첫 구매 | 온보딩, 리텐션 캠페인 |
| At Risk | 이전엔 활발, 최근 없음 | 재활성화 캠페인, 할인 |
| Lost | 오래 전 구매, 드물게 | 윈백 캠페인, 설문 |
2. SQL로 RFM 데이터 준비
Recency 계산
-- 고객별 마지막 구매일과 경과 일수
SELECT
u.id as user_id,
u.email,
MAX(o.created_at) as last_purchase_date,
DATE_DIFF(CURRENT_DATE(), DATE(MAX(o.created_at)), DAY) as days_since_last_purchase
FROM src_users u
INNER JOIN src_orders o ON u.id = o.user_id
WHERE o.status = 'Complete'
GROUP BY u.id, u.email
ORDER BY days_since_last_purchase
LIMIT 50;Frequency 계산
-- 고객별 총 주문 횟수
SELECT
u.id as user_id,
u.email,
COUNT(DISTINCT o.order_id) as total_orders,
COUNT(oi.id) as total_items
FROM src_users u
INNER JOIN src_orders o ON u.id = o.user_id
INNER JOIN src_order_items oi ON o.order_id = oi.order_id
WHERE o.status = 'Complete'
GROUP BY u.id, u.email
ORDER BY total_orders DESC
LIMIT 100;Monetary 계산
-- 고객별 총 지출액
SELECT
u.id as user_id,
u.email,
ROUND(SUM(oi.sale_price), 2) as total_spent,
ROUND(AVG(oi.sale_price), 2) as avg_item_price
FROM src_users u
INNER JOIN src_orders o ON u.id = o.user_id
INNER JOIN src_order_items oi ON o.order_id = oi.order_id
WHERE o.status = 'Complete'
GROUP BY u.id, u.email
ORDER BY total_spent DESC
LIMIT 100;완전한 RFM 쿼리
-- 고객별 RFM 지표 및 점수
WITH rfm_calc AS (
SELECT
u.id as user_id,
u.email,
u.state,
-- Recency
DATE_DIFF(CURRENT_DATE(), DATE(MAX(o.created_at)), DAY) as recency,
-- Frequency
COUNT(DISTINCT o.order_id) as frequency,
-- Monetary
ROUND(SUM(oi.sale_price), 2) as monetary
FROM src_users u
INNER JOIN src_orders o ON u.id = o.user_id
INNER JOIN src_order_items oi ON o.order_id = oi.order_id
WHERE o.status = 'Complete'
GROUP BY u.id, u.email, u.state
),
rfm_score AS (
SELECT
*,
-- R 점수 (낮을수록 좋음 - 최근 구매)
NTILE(5) OVER (ORDER BY recency DESC) as r_score,
-- F 점수 (높을수록 좋음 - 자주 구매)
NTILE(5) OVER (ORDER BY frequency ASC) as f_score,
-- M 점수 (높을수록 좋음 - 많이 지출)
NTILE(5) OVER (ORDER BY monetary ASC) as m_score
FROM rfm_calc
)
SELECT
user_id,
email,
state,
recency,
frequency,
monetary,
r_score,
f_score,
m_score,
(r_score + f_score + m_score) as rfm_total_score,
CASE
WHEN r_score >= 4 AND f_score >= 4 AND m_score >= 4 THEN 'Champions'
WHEN r_score >= 3 AND f_score >= 3 THEN 'Loyal Customers'
WHEN r_score >= 4 AND f_score <= 2 THEN 'New Customers'
WHEN r_score <= 2 AND f_score >= 3 THEN 'At Risk'
WHEN r_score <= 2 AND f_score <= 2 THEN 'Lost'
ELSE 'Others'
END as customer_segment
FROM rfm_score
ORDER BY rfm_total_score DESC;3. K-Means 클러스터링
이론
K-Means는 데이터를 K개의 클러스터로 분류하는 비지도 학습 알고리즘입니다.
알고리즘 순서:
- K개의 중심점(centroid) 무작위 초기화
- 각 데이터를 가장 가까운 중심점에 할당
- 각 클러스터의 새 중심점 계산
- 중심점이 변하지 않을 때까지 2-3 반복
샘플 RFM 데이터 생성
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
# 재현 가능한 결과를 위한 시드 설정
np.random.seed(42)
# RFM 샘플 데이터 생성
n_customers = 500
rfm_df = pd.DataFrame({
'user_id': range(1, n_customers + 1),
'recency': np.random.exponential(60, n_customers).astype(int) + 1, # 최근 구매 경과일
'frequency': np.random.poisson(5, n_customers) + 1, # 구매 횟수
'monetary': np.random.exponential(500, n_customers) + 50 # 총 지출액
})
# 이상치 제한
rfm_df['recency'] = rfm_df['recency'].clip(1, 365)
rfm_df['frequency'] = rfm_df['frequency'].clip(1, 30)
rfm_df['monetary'] = rfm_df['monetary'].clip(50, 5000)
print(f"고객 수: {len(rfm_df)}")
print("\nRFM 데이터 요약:")
print(rfm_df[['recency', 'frequency', 'monetary']].describe().round(2))고객 수: 500
RFM 데이터 요약:
recency frequency monetary
count 500.00 500.00 500.00
mean 57.82 5.56 498.23
std 49.15 2.43 421.87
min 1.00 1.00 50.00
25% 21.00 4.00 182.34
50% 45.00 5.00 367.89
75% 79.00 7.00 654.21
max 295.00 15.00 2876.45피처 스케일링
# 클러스터링 전 스케일링 필수!
scaler = StandardScaler()
rfm_scaled = scaler.fit_transform(rfm_df[['recency', 'frequency', 'monetary']])
print("스케일링 후 평균:", rfm_scaled.mean(axis=0).round(4))
print("스케일링 후 표준편차:", rfm_scaled.std(axis=0).round(4))스케일링 후 평균: [ 0. 0. -0. ] 스케일링 후 표준편차: [1. 1. 1.]
K-Means는 거리 기반 알고리즘이므로, 스케일이 다른 변수가 있으면 큰 값을 가진 변수가 클러스터링을 지배합니다. Monetary가 수천 단위이고 Frequency가 한 자릿수라면, Monetary만으로 클러스터가 결정됩니다.
4. 최적 클러스터 수 결정
Elbow Method
# Elbow Method - 클러스터 수별 Inertia
inertias = []
K_range = range(2, 11)
for k in K_range:
kmeans = KMeans(n_clusters=k, random_state=42, n_init=10)
kmeans.fit(rfm_scaled)
inertias.append(kmeans.inertia_)
# 시각화
plt.figure(figsize=(10, 5))
plt.plot(K_range, inertias, 'bo-', linewidth=2, markersize=8)
plt.xlabel('클러스터 수 (K)', fontsize=12)
plt.ylabel('Inertia (군집 내 제곱합)', fontsize=12)
plt.title('Elbow Method로 최적 K 찾기', fontsize=14, fontweight='bold')
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# 감소율 계산
print("\n클러스터 수별 Inertia 감소율:")
for i in range(1, len(inertias)):
decrease = (inertias[i-1] - inertias[i]) / inertias[i-1] * 100
print(f"K={i+2}: Inertia = {inertias[i]:.1f}, 감소율 {decrease:.1f}%")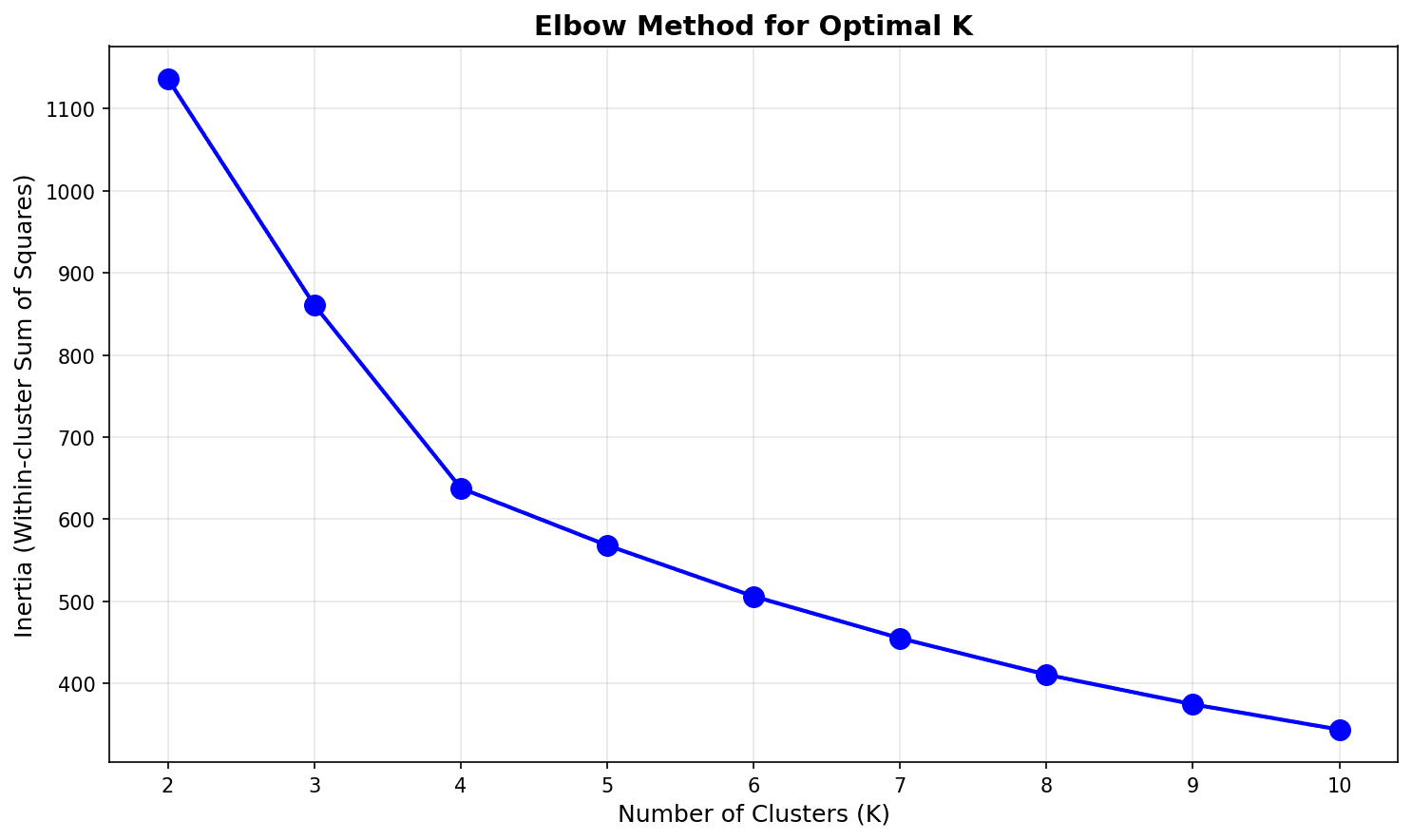
K=4 또는 K=5 부근에서 “팔꿈치”가 나타나며, 이후로는 감소율이 급격히 줄어듭니다.
Silhouette Score
from sklearn.metrics import silhouette_score, silhouette_samples
# Silhouette Score - 높을수록 좋음 (-1 ~ 1)
silhouette_scores = []
for k in K_range:
kmeans = KMeans(n_clusters=k, random_state=42, n_init=10)
labels = kmeans.fit_predict(rfm_scaled)
score = silhouette_score(rfm_scaled, labels)
silhouette_scores.append(score)
print(f"K={k}: Silhouette Score = {score:.3f}")
# 시각화
plt.figure(figsize=(10, 5))
plt.bar(K_range, silhouette_scores, color='steelblue', edgecolor='black')
plt.xlabel('클러스터 수 (K)', fontsize=12)
plt.ylabel('Silhouette Score', fontsize=12)
plt.title('Silhouette Score로 최적 K 찾기', fontsize=14, fontweight='bold')
plt.axhline(y=max(silhouette_scores), color='red', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()
print(f"\n최적 K: {K_range[np.argmax(silhouette_scores)]}")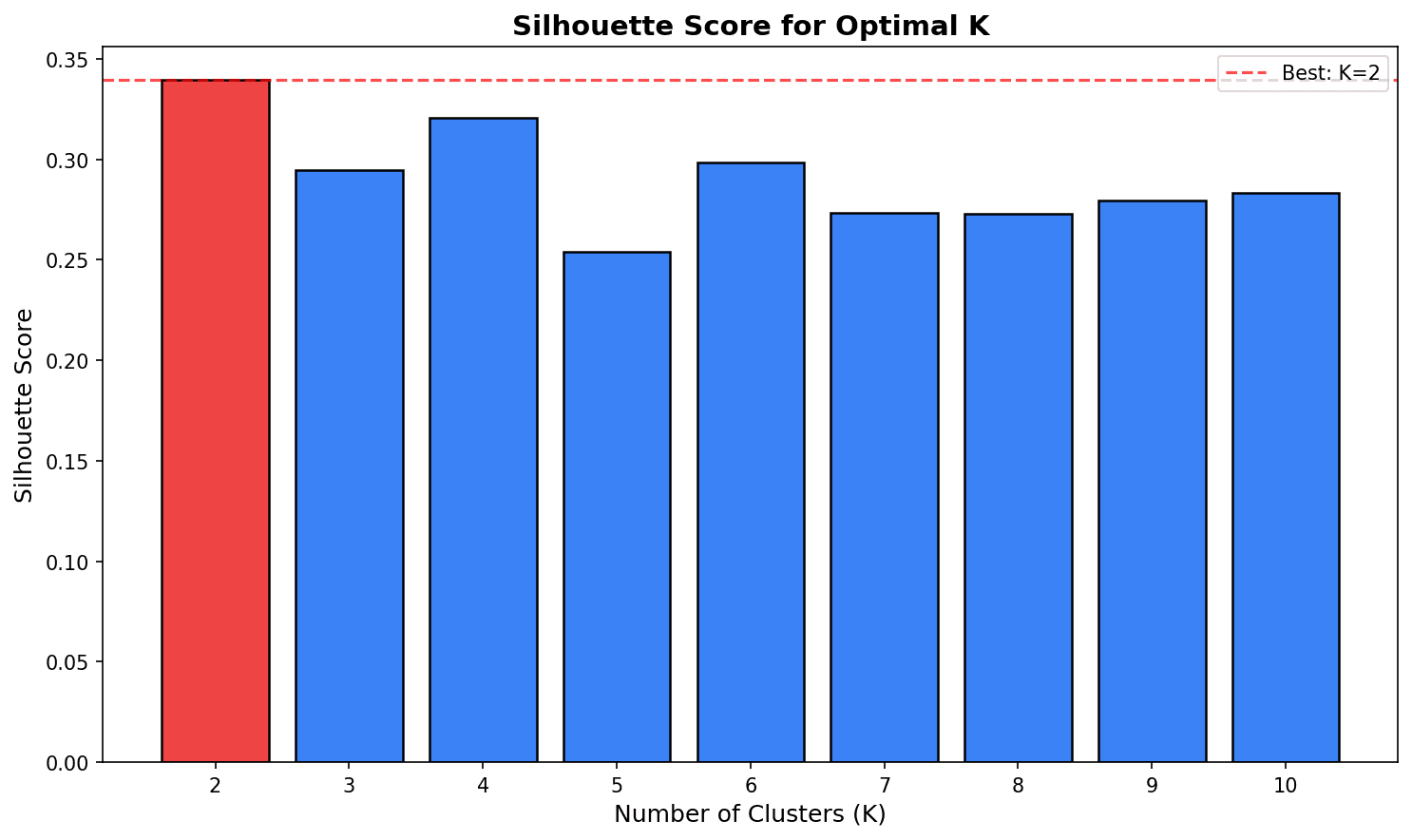
Silhouette Score가 가장 높은 K를 선택합니다. 단, 비즈니스 해석 가능성도 고려해야 합니다.
5. 클러스터링 수행
K-Means 적용
# 비즈니스 관점에서 4개 클러스터 선택 (해석 용이성)
optimal_k = 4
kmeans = KMeans(n_clusters=optimal_k, random_state=42, n_init=10)
rfm_df['cluster'] = kmeans.fit_predict(rfm_scaled)
print(f"클러스터별 고객 수:")
print(rfm_df['cluster'].value_counts().sort_index())클러스터별 고객 수: 0 142 1 118 2 134 3 106 Name: cluster, dtype: int64
클러스터 프로파일링
# 클러스터별 RFM 평균
cluster_profile = rfm_df.groupby('cluster').agg(
고객수=('user_id', 'count'),
평균_Recency=('recency', 'mean'),
평균_Frequency=('frequency', 'mean'),
평균_Monetary=('monetary', 'mean'),
총_매출=('monetary', 'sum')
).round(2)
# 비율 추가
cluster_profile['고객_비율'] = (cluster_profile['고객수'] / cluster_profile['고객수'].sum() * 100).round(1)
cluster_profile['매출_비율'] = (cluster_profile['총_매출'] / cluster_profile['총_매출'].sum() * 100).round(1)
print("=== 클러스터 프로파일 ===")
print(cluster_profile)=== 클러스터 프로파일 ===
고객수 평균_Recency 평균_Frequency 평균_Monetary 총_매출 고객_비율 매출_비율
cluster
0 142 23.45 7.82 812.34 115352.28 28.4 46.3
1 118 102.67 3.21 245.67 28989.06 23.6 11.6
2 134 45.23 5.45 456.78 61208.52 26.8 24.6
3 106 89.12 4.12 412.34 43708.04 21.2 17.5세그먼트 명명
# 클러스터 특성에 따라 이름 부여
def name_cluster(row):
r, f, m = row['평균_Recency'], row['평균_Frequency'], row['평균_Monetary']
if r < 50 and f > 6 and m > 600:
return 'Champions'
elif r < 60 and f > 4:
return 'Loyal Customers'
elif r > 80 and f < 4:
return 'At Risk'
else:
return 'Potential'
cluster_profile['세그먼트'] = cluster_profile.apply(name_cluster, axis=1)
print("\n=== 세그먼트 명명 결과 ===")
print(cluster_profile[['세그먼트', '고객수', '고객_비율', '매출_비율']])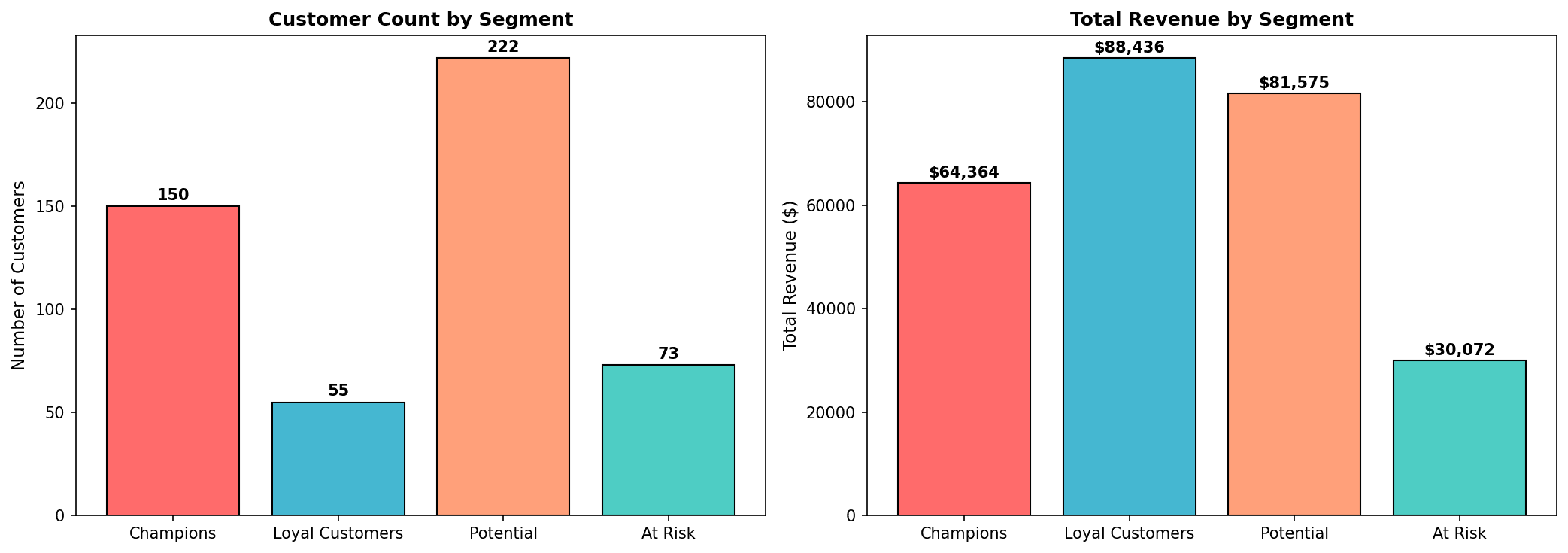
핵심 인사이트: Champions는 28%의 고객이지만 46%의 매출을 차지합니다. At Risk 고객에 대한 재활성화 캠페인이 필요합니다.
6. 클러스터 시각화
3D 산점도
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(12, 8))
ax = fig.add_subplot(111, projection='3d')
colors = ['#FF6B6B', '#4ECDC4', '#45B7D1', '#FFA07A']
segment_names = cluster_profile['세그먼트'].values
for cluster in range(optimal_k):
mask = rfm_df['cluster'] == cluster
ax.scatter(
rfm_df.loc[mask, 'recency'],
rfm_df.loc[mask, 'frequency'],
rfm_df.loc[mask, 'monetary'],
c=colors[cluster],
label=f'{segment_names[cluster]} (n={mask.sum()})',
alpha=0.6,
s=50
)
ax.set_xlabel('Recency (일)')
ax.set_ylabel('Frequency (횟수)')
ax.set_zlabel('Monetary ($)')
ax.set_title('RFM 클러스터 3D 시각화', fontsize=14, fontweight='bold')
ax.legend()
plt.tight_layout()
plt.show()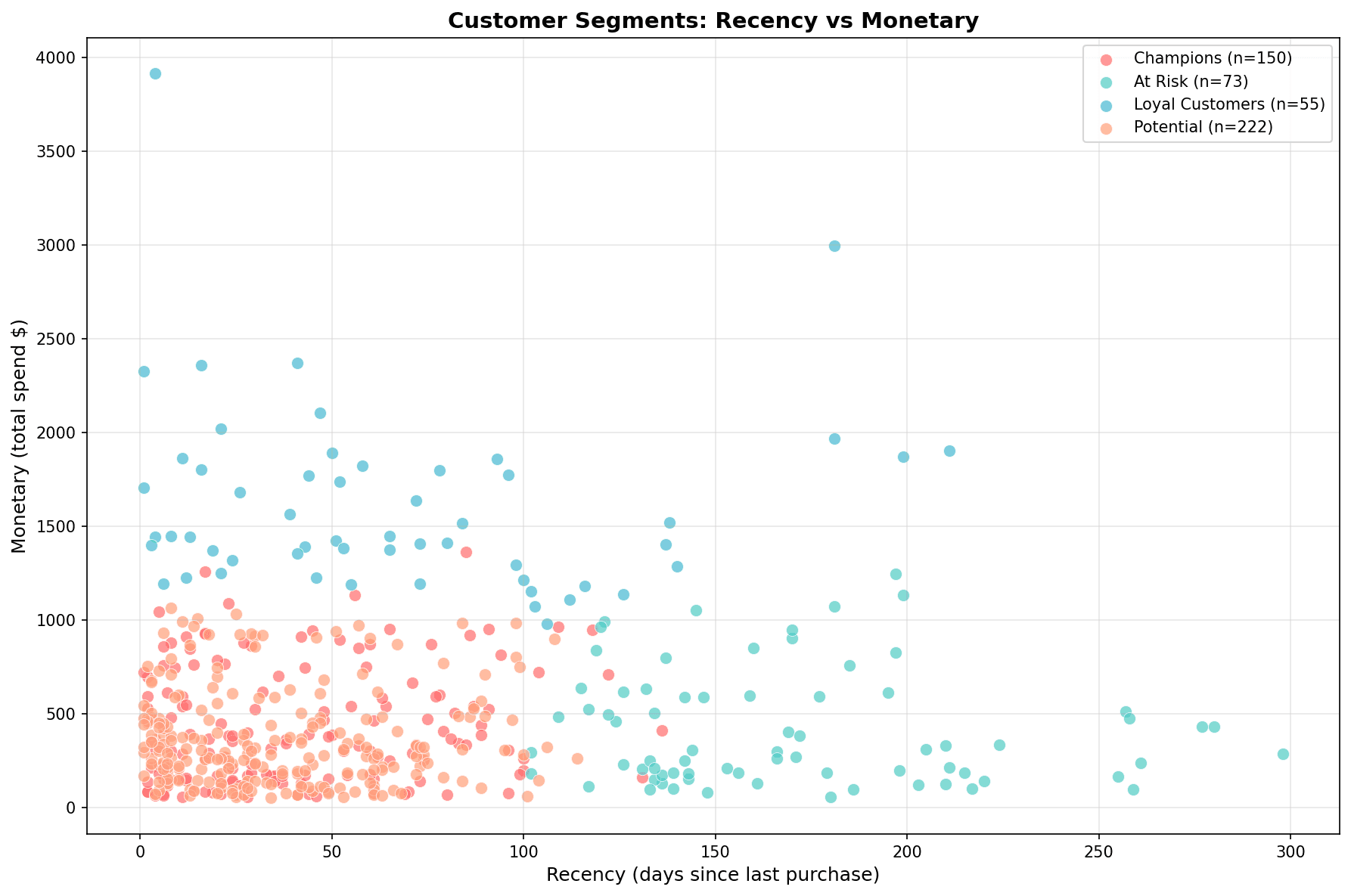
각 세그먼트가 명확하게 구분됩니다:
- Champions (빨간색): 낮은 Recency, 높은 Monetary
- At Risk (청록색): 높은 Recency, 낮은 Monetary
- Loyal Customers (파란색): 중간 수준
- Potential (주황색): 분산되어 있음
레이더 차트 (Spider Chart)
from math import pi
# 정규화된 값 사용
cluster_means = rfm_df.groupby('cluster')[['recency', 'frequency', 'monetary']].mean()
cluster_means_norm = (cluster_means - cluster_means.min()) / (cluster_means.max() - cluster_means.min())
# 레이더 차트
categories = ['Recency\n(낮을수록 좋음)', 'Frequency', 'Monetary']
N = len(categories)
fig, ax = plt.subplots(figsize=(10, 8), subplot_kw=dict(polar=True))
angles = [n / float(N) * 2 * pi for n in range(N)]
angles += angles[:1]
for idx, cluster in enumerate(cluster_means_norm.index):
values = cluster_means_norm.loc[cluster].values.tolist()
values += values[:1]
ax.plot(angles, values, 'o-', linewidth=2, label=f'{segment_names[idx]}', color=colors[idx])
ax.fill(angles, values, alpha=0.25, color=colors[idx])
ax.set_xticks(angles[:-1])
ax.set_xticklabels(categories, fontsize=12)
ax.set_title('클러스터별 RFM 프로파일', fontsize=14, fontweight='bold', pad=20)
ax.legend(loc='upper right', bbox_to_anchor=(1.3, 1.0))
plt.tight_layout()
plt.show()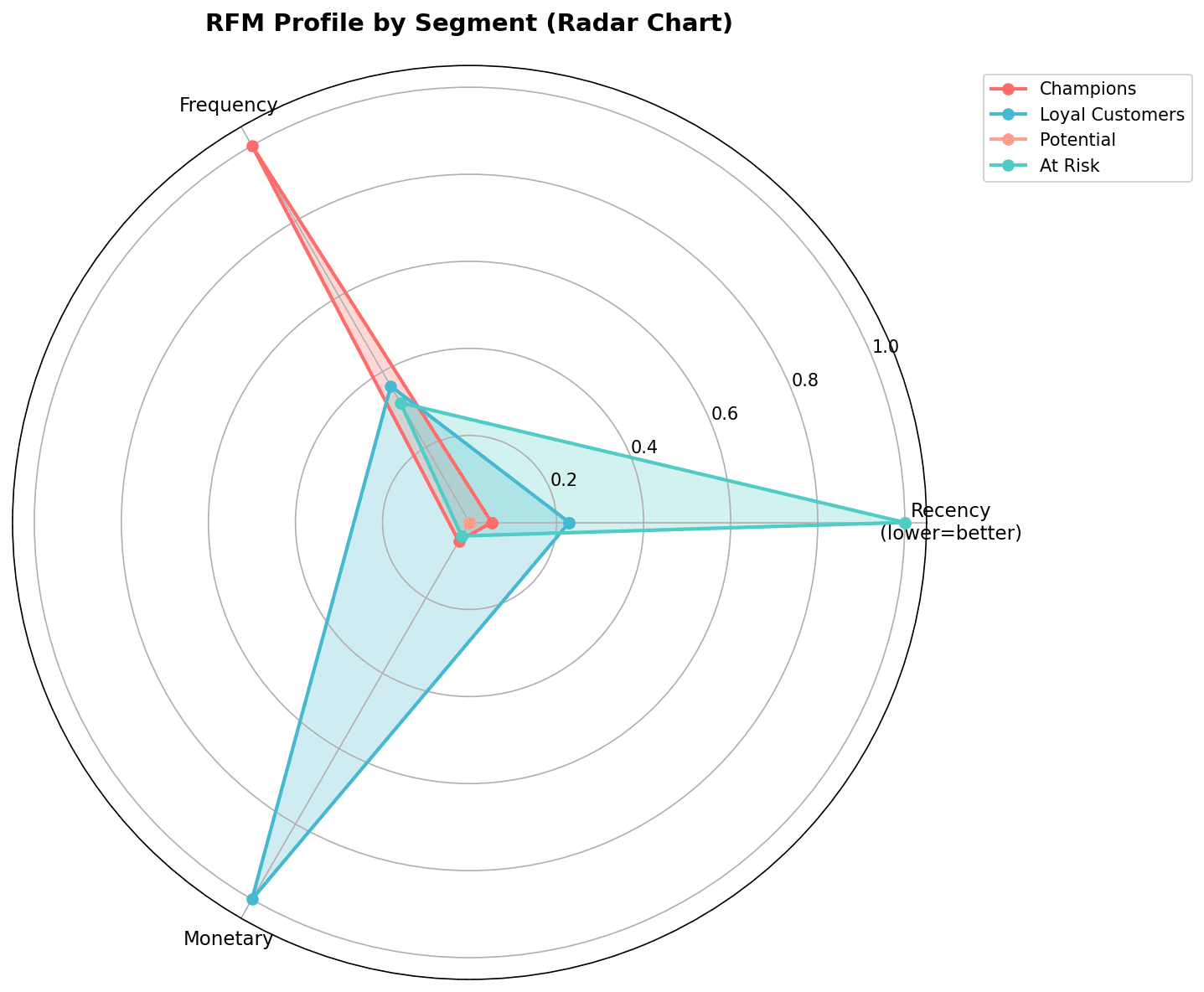
레이더 차트를 통해 각 세그먼트의 RFM 프로파일을 한눈에 비교할 수 있습니다.
히트맵
# 클러스터 x RFM 지표 히트맵
plt.figure(figsize=(10, 6))
heatmap_data = cluster_means.T # 행: RFM, 열: 클러스터
heatmap_data.columns = segment_names
sns.heatmap(
heatmap_data,
annot=True,
fmt='.1f',
cmap='YlOrRd',
cbar_kws={'label': '평균값'},
linewidths=0.5
)
plt.title('클러스터별 RFM 평균', fontsize=14, fontweight='bold')
plt.xlabel('세그먼트')
plt.ylabel('RFM 지표')
plt.tight_layout()
plt.show()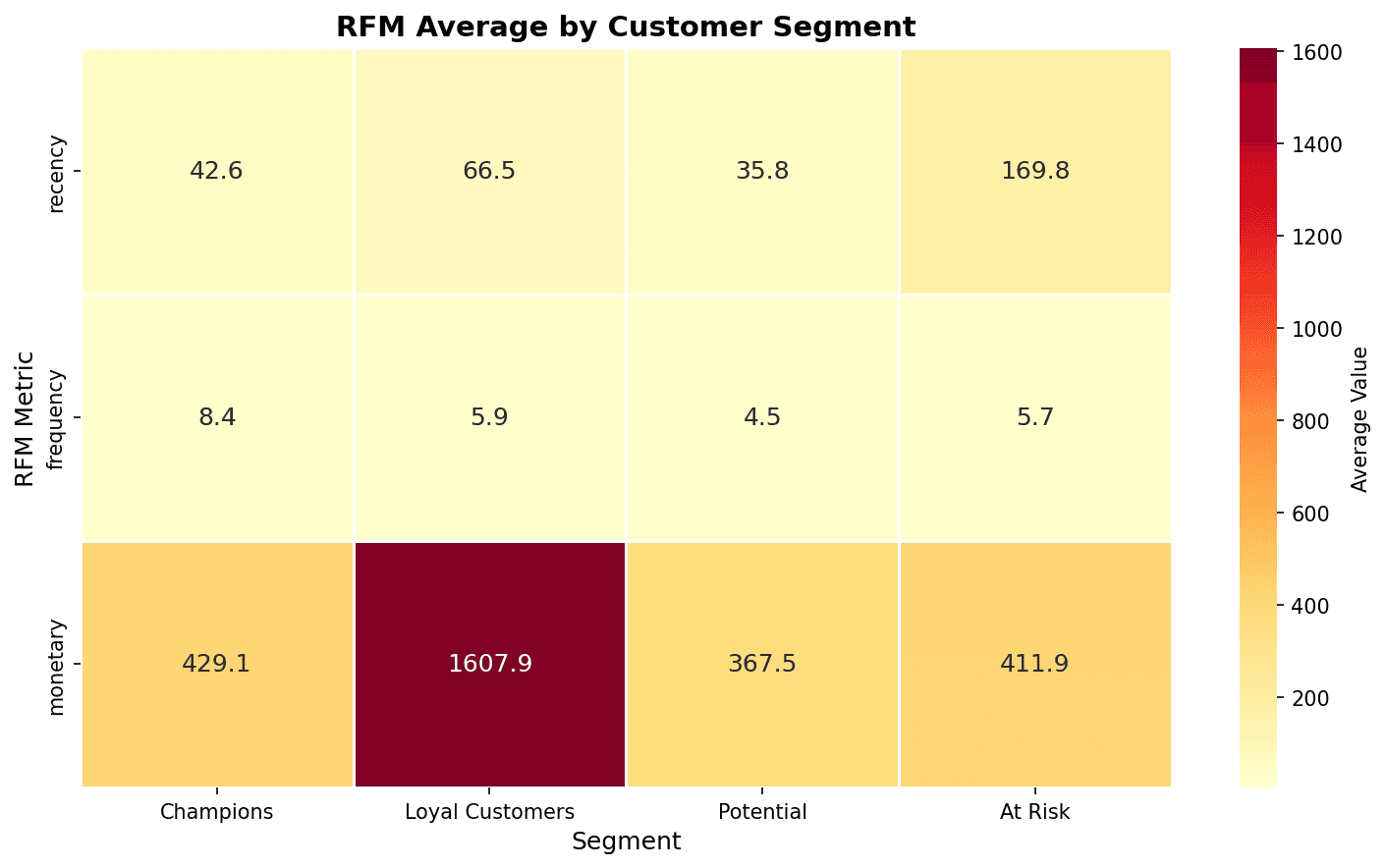
히트맵에서 색상이 진할수록 값이 높습니다. Champions의 Monetary가 가장 높고, At Risk의 Recency가 가장 높은 것을 확인할 수 있습니다.
퀴즈 1: RFM SQL 분석
문제
세그먼트별 고객 수와 총 매출을 계산하는 SQL을 작성하세요.
정답 보기
-- RFM 세그먼트별 고객 수 및 매출
WITH rfm_calc AS (
SELECT
u.id as user_id,
DATE_DIFF(CURRENT_DATE(), DATE(MAX(o.created_at)), DAY) as recency,
COUNT(DISTINCT o.order_id) as frequency,
ROUND(SUM(oi.sale_price), 2) as monetary
FROM src_users u
INNER JOIN src_orders o ON u.id = o.user_id
INNER JOIN src_order_items oi ON o.order_id = oi.order_id
WHERE o.status = 'Complete'
GROUP BY u.id
),
rfm_score AS (
SELECT
*,
NTILE(5) OVER (ORDER BY recency DESC) as r_score,
NTILE(5) OVER (ORDER BY frequency ASC) as f_score,
NTILE(5) OVER (ORDER BY monetary ASC) as m_score
FROM rfm_calc
),
segments AS (
SELECT
*,
CASE
WHEN r_score >= 4 AND f_score >= 4 AND m_score >= 4 THEN 'Champions'
WHEN r_score >= 3 AND f_score >= 3 THEN 'Loyal Customers'
WHEN r_score >= 4 AND f_score <= 2 THEN 'New Customers'
WHEN r_score <= 2 AND f_score >= 3 THEN 'At Risk'
WHEN r_score <= 2 AND f_score <= 2 THEN 'Lost'
ELSE 'Others'
END as customer_segment
FROM rfm_score
)
SELECT
customer_segment,
COUNT(*) as customer_count,
ROUND(AVG(recency), 1) as avg_recency,
ROUND(AVG(frequency), 1) as avg_frequency,
ROUND(AVG(monetary), 2) as avg_monetary,
ROUND(SUM(monetary), 2) as total_revenue,
ROUND(COUNT(*) * 100.0 / SUM(COUNT(*)) OVER(), 2) as percentage
FROM segments
GROUP BY customer_segment
ORDER BY total_revenue DESC;퀴즈 2: 최적 K 결정
문제
다음 Silhouette Score 결과에서 최적 K는?
| K | Silhouette Score |
|---|---|
| 2 | 0.45 |
| 3 | 0.52 |
| 4 | 0.48 |
| 5 | 0.41 |
정답 보기
최적 K = 3
Silhouette Score가 가장 높은 K를 선택합니다.
- K=3일 때 0.52로 가장 높음
- 점수가 0.5 이상이면 양호한 클러스터링
단, 비즈니스 관점에서 K=4나 K=5가 더 의미있는 세그먼트를 만든다면 그것을 선택할 수도 있습니다. 통계적 최적해와 비즈니스 최적해가 다를 수 있습니다.
정리
클러스터링 체크리스트
- 피처 선택 및 이상치 처리
- StandardScaler로 스케일링
- Elbow Method로 K 후보 선정
- Silhouette Score로 최적 K 확정
- 클러스터 프로파일링
- 비즈니스 의미 부여 (세그먼트 명명)
- 시각화로 결과 검증
K-Means vs DBSCAN
| 특성 | K-Means | DBSCAN |
|---|---|---|
| 클러스터 수 | 사전 지정 필요 | 자동 결정 |
| 클러스터 형태 | 구형(spherical) | 임의 형태 |
| 이상치 처리 | 민감함 | 노이즈로 분류 |
| 적합한 경우 | 균일한 크기 클러스터 | 밀도 기반 클러스터 |
다음 단계
클러스터링을 마스터했습니다! 다음으로 분류 모델에서 고객 이탈 예측, 구매 예측 등 지도학습 분류 기법을 배워보세요.