히트맵 시각화
중급
학습 목표
이 레시피를 완료하면 다음을 할 수 있습니다:
- Seaborn으로 히트맵 생성
- 요일 × 시간대 패턴 분석
- 상관관계 히트맵 만들기
- 코호트 리텐션 히트맵 분석
0. 사전 준비 (Setup)
데이터 실습을 위해 CSV 파일을 로드합니다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 한글 폰트 설정 (폰트가 없을 경우 기본값 사용)
plt.rcParams['font.family'] = 'sans-serif'
plt.rcParams['axes.unicode_minus'] = False
# Load Data
orders = pd.read_csv('src_orders.csv', parse_dates=['created_at'])
items = pd.read_csv('src_order_items.csv')
products = pd.read_csv('src_products.csv')
# Merge for Heatmap Analysis
df = orders.merge(items, on='order_id').merge(products, on='product_id')
# Ensure datetime conversion
df['created_at'] = pd.to_datetime(df['created_at'], format='mixed')1. 기본 환경 설정
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 한글 폰트 설정
plt.rcParams['font.family'] = 'NanumGothic' # Linux
# plt.rcParams['font.family'] = 'AppleGothic' # macOS
# plt.rcParams['font.family'] = 'Malgun Gothic' # Windows
plt.rcParams['axes.unicode_minus'] = False
# 기본 스타일
plt.style.use('seaborn-v0_8-whitegrid')2. 요일 × 시간대 히트맵
이론
요일과 시간대별 패턴을 히트맵으로 시각화하면 피크 타임을 한눈에 파악할 수 있습니다.
SQL로 데이터 준비
BigQuery:
SELECT
EXTRACT(DAYOFWEEK FROM created_at) as day_of_week,
EXTRACT(HOUR FROM created_at) as hour_of_day,
COUNT(*) as order_count
FROM `project.dataset.src_orders`
WHERE DATE(created_at) >= '2023-01-01'
GROUP BY day_of_week, hour_of_day
ORDER BY day_of_week, hour_of_dayPandas:
# datetime 추출
df['day_of_week'] = df['created_at'].dt.dayofweek + 1 # 1=월요일
df['hour_of_day'] = df['created_at'].dt.hour
# 그룹화
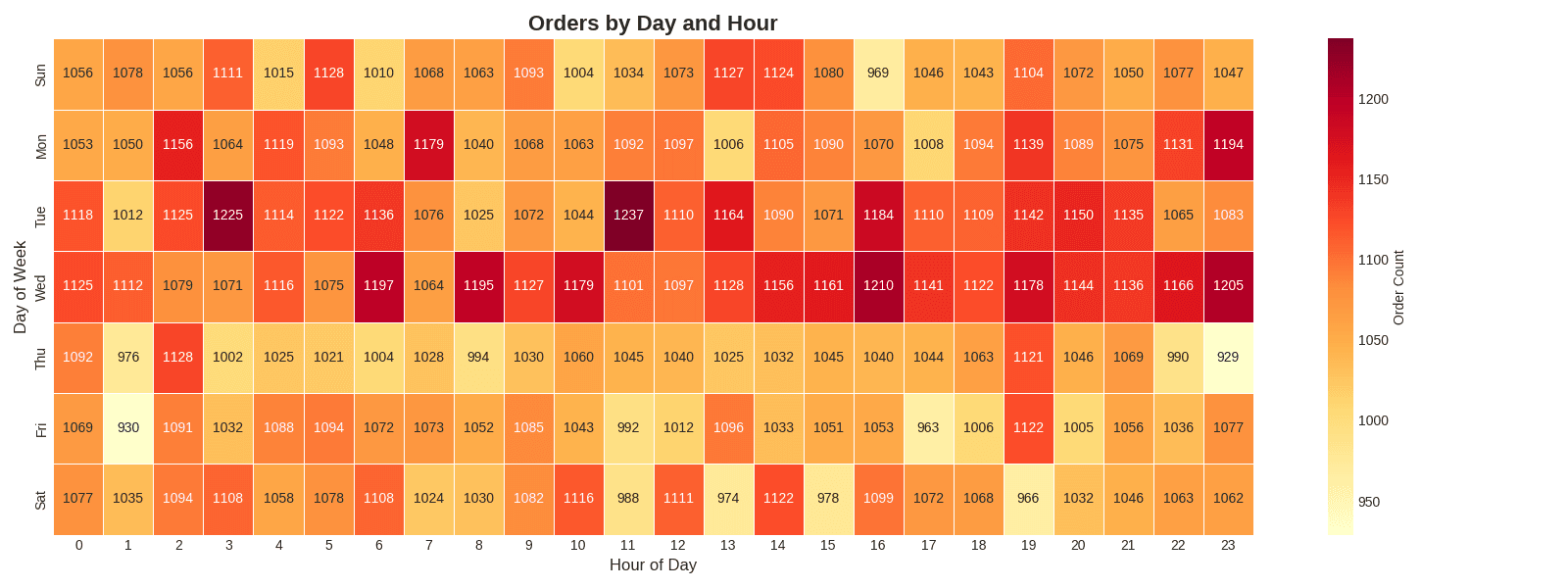
hourly = df.groupby(['day_of_week', 'hour_of_day']).size().reset_index(name='order_count')히트맵 시각화
# 피벗 테이블 생성 (요일 × 시간)
heatmap_data = hourly.pivot(
index='day_of_week',
columns='hour_of_day',
values='order_count'
)
heatmap_data = heatmap_data.fillna(0).astype(float)
# 요일 라벨 매핑 (English Labels)
day_labels = ['Sun', 'Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat']
heatmap_data.index = [day_labels[int(i)-1] for i in heatmap_data.index]
# 히트맵 그리기
plt.figure(figsize=(16, 6))
sns.heatmap(
heatmap_data,
annot=True, # 값 표시
fmt='.0f', # 정수 형식
cmap='YlOrRd', # 색상 팔레트
cbar_kws={'label': 'Order Count'},
linewidths=0.5 # 셀 구분선
)
plt.title('Orders by Day and Hour', fontsize=16, fontweight='bold')
plt.xlabel('Hour of Day', fontsize=12)
plt.ylabel('Day of Week', fontsize=12)
plt.tight_layout()
plt.show()
# 인사이트
print(f"📊 Peak Time: {heatmap_data.max().idxmax()}h")
print(f"📊 Peak Day: {heatmap_data.max(axis=1).idxmax()}")실행 결과
[Graph Saved: generated_plot_90d238ffde_0.png] 📊 Peak Time: 11h 📊 Peak Day: Tue
주요 파라미터
| 파라미터 | 설명 | 예시 |
|---|---|---|
annot | 값 표시 여부 | True, False |
fmt | 숫자 형식 | .0f, .2f, .1% |
cmap | 색상 팔레트 | YlOrRd, Blues, RdYlGn |
linewidths | 셀 구분선 두께 | 0.5, 1 |
cbar_kws | 컬러바 설정 | {'label': 'Order Count'} |
vmin, vmax | 색상 범위 | vmin=0, vmax=100 |
3. 카테고리 × 월별 매출 히트맵
SQL 쿼리
SELECT
p.category,
EXTRACT(MONTH FROM DATE(o.created_at)) as month,
SUM(oi.sale_price) as revenue
FROM src_orders o
JOIN src_order_items oi ON o.order_id = oi.order_id
JOIN src_products p ON oi.product_id = p.product_id
WHERE EXTRACT(YEAR FROM o.created_at) = 2023
GROUP BY category, month
ORDER BY category, month시각화 코드
# Month & Revenue Calculation
df['month'] = df['created_at'].dt.month
df['revenue'] = df['sale_price']
# Group by Category & Month
monthly_cat = df.groupby(['category', 'month'])['revenue'].sum().reset_index()
# Pivot Table
heatmap_data = monthly_cat.pivot(index='category', columns='month', values='revenue')
heatmap_data = heatmap_data.fillna(0)
# Month Labels (English)
month_labels = ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun',
'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec']
heatmap_data.columns = [month_labels[int(i)-1] for i in heatmap_data.columns]
# Top 10 Categories
top_categories = heatmap_data.sum(axis=1).nlargest(10).index
heatmap_data_top = heatmap_data.loc[top_categories]
# Heatmap
plt.figure(figsize=(14, 8))
sns.heatmap(heatmap_data_top, annot=True, fmt='.0f', cmap='Blues',
cbar_kws={'label': 'Revenue ($)'}, linewidths=0.5)
plt.title('Monthly Revenue by Category (Top 10)', fontsize=16, fontweight='bold')
plt.xlabel('Month', fontsize=12)
plt.ylabel('Category', fontsize=12)
plt.tight_layout()
plt.show()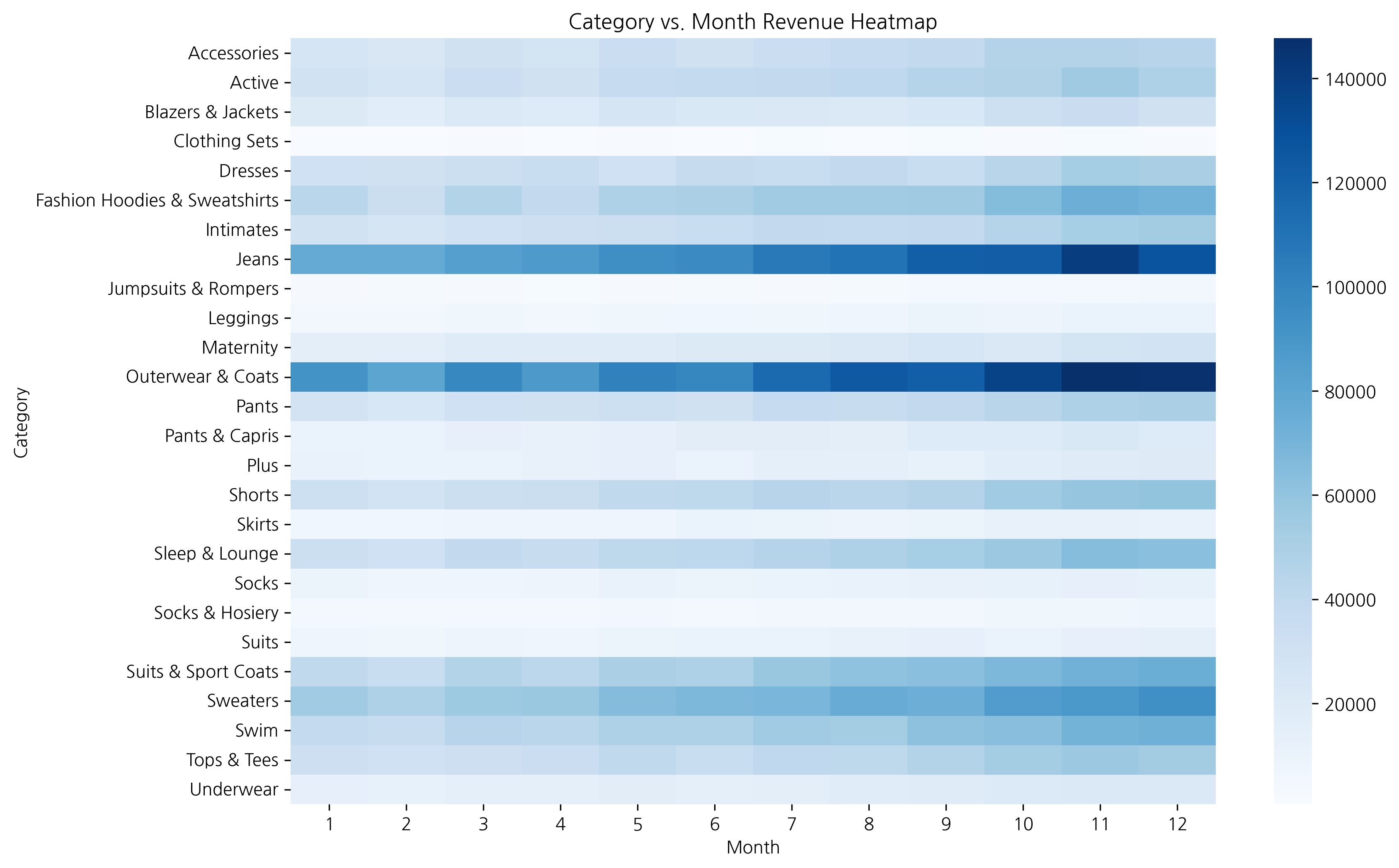
ℹ️
데이터 범위가 클 경우 annot=False로 설정하여 숫자 겹침을 방지하고 색상만으로 패턴을 보는 것이 좋습니다.
4. 상관관계 히트맵
이론
수치형 변수들 간의 상관관계를 히트맵으로 시각화합니다. 상관계수는 -1 ~ 1 사이의 값을 가지며:
- 1에 가까움: 강한 양의 상관관계
- -1에 가까움: 강한 음의 상관관계
- 0에 가까움: 상관관계 없음
상관관계 계산 및 시각화
# Calculate Derived Metrics
df['profit'] = df['sale_price'] - df['cost']
df['profit_margin'] = (df['profit'] / df['sale_price']).fillna(0)
# Select Numeric Columns
numeric_cols = ['retail_price', 'cost', 'sale_price', 'profit', 'profit_margin']
corr_data = df[numeric_cols]
# Correlation Matrix
corr_matrix = corr_data.corr()
# Heatmap
plt.figure(figsize=(10, 8))
sns.heatmap(
corr_matrix,
annot=True, # Show values
fmt='.2f', # 2 decimals
cmap='RdYlBu_r', # Palette
vmin=-1, vmax=1, # Range
center=0, # Center
square=True, # Square cells
linewidths=0.5
)
plt.title('Correlation Heatmap', fontsize=16, fontweight='bold')
plt.tight_layout()
plt.show()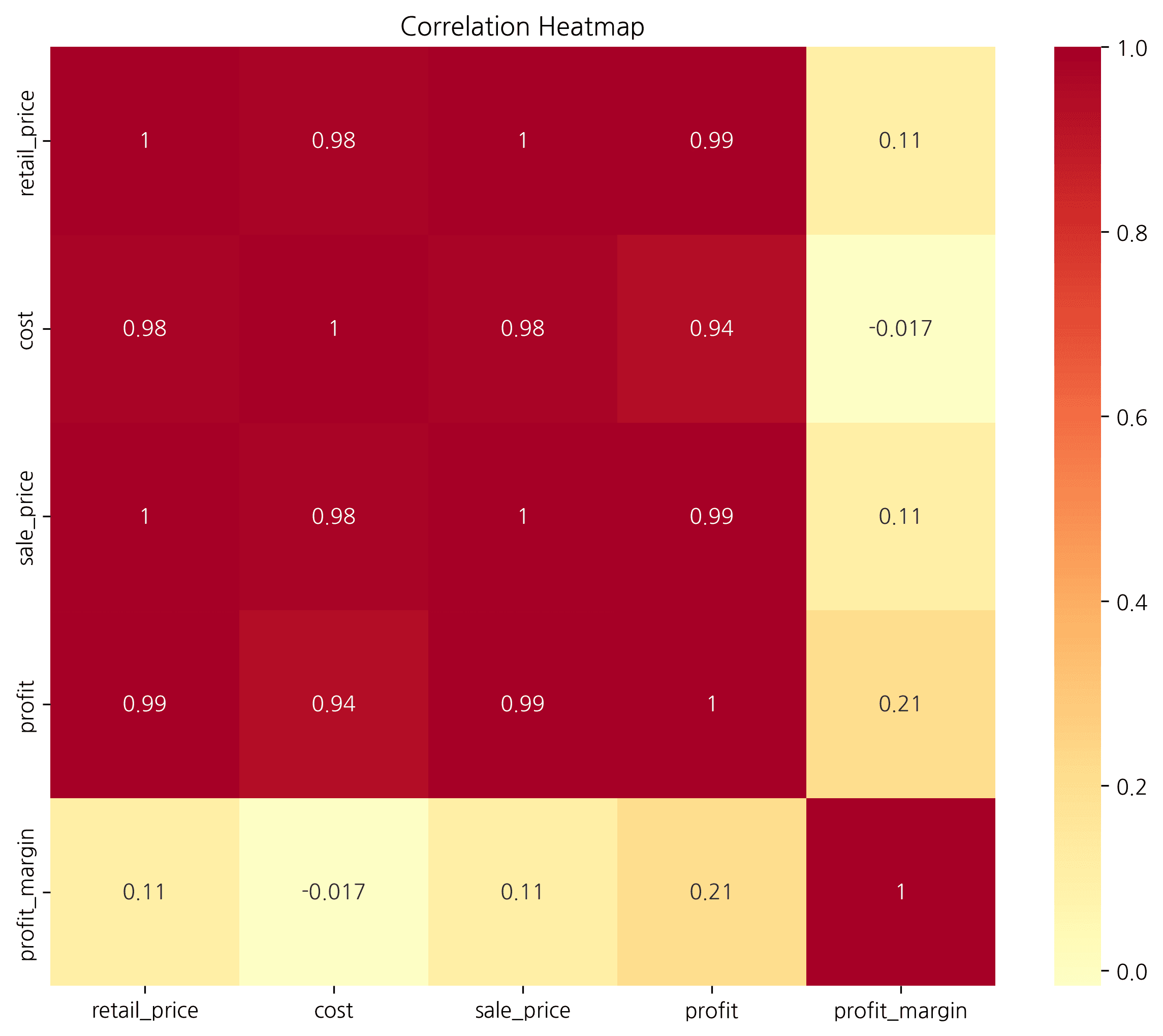
ℹ️
주말(Sat, Sun)과 평일, 그리고 점심/저녁 시간대의 주문 패턴 차이를 쉽게 발견할 수 있습니다.
마스크로 하삼각형만 표시
# 상삼각 마스크 생성
mask = np.triu(np.ones_like(corr_matrix, dtype=bool))
plt.figure(figsize=(10, 8))
sns.heatmap(
corr_matrix,
mask=mask, # 마스크 적용
annot=True,
fmt='.2f',
cmap='RdYlBu_r',
vmin=-1, vmax=1,
center=0,
square=True
)
plt.title('상관관계 히트맵 (하삼각)', fontsize=16, fontweight='bold')
plt.tight_layout()
plt.show()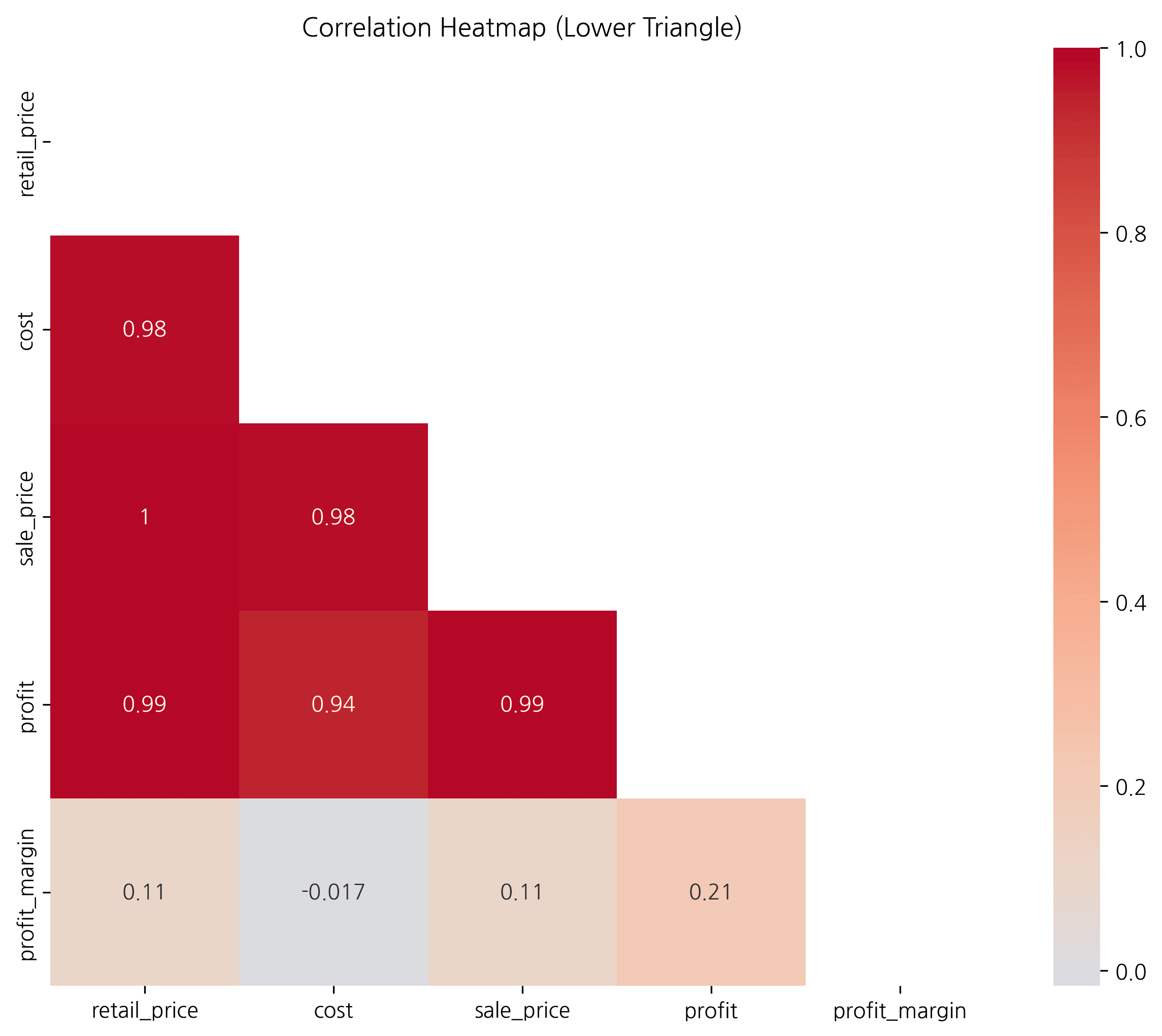
5. 코호트 리텐션 히트맵
이론
코호트 분석은 같은 시기에 가입/구매한 고객 그룹의 행동을 추적합니다. 리텐션 히트맵은 시간이 지남에 따른 고객 유지율을 보여줍니다.
SQL 쿼리
WITH user_cohorts AS (
SELECT
user_id,
DATE_TRUNC(MIN(DATE(created_at)), MONTH) as cohort_month
FROM src_orders
GROUP BY user_id
),
user_activities AS (
SELECT
o.user_id,
DATE_TRUNC(DATE(o.created_at), MONTH) as activity_month
FROM src_orders o
GROUP BY o.user_id, DATE_TRUNC(DATE(o.created_at), MONTH)
)
SELECT
FORMAT_DATE('%Y-%m', c.cohort_month) as cohort,
DATE_DIFF(a.activity_month, c.cohort_month, MONTH) as months_since_first,
COUNT(DISTINCT a.user_id) as active_users
FROM user_cohorts c
JOIN user_activities a ON c.user_id = a.user_id
WHERE c.cohort_month >= '2023-01-01'
GROUP BY cohort, months_since_first
ORDER BY cohort, months_since_first리텐션 히트맵 시각화
# 1. 유저별 최초 구매월(Cohort) 계산
df['order_month'] = df['created_at'].dt.to_period('M')
user_cohort = df.groupby('user_id')['order_month'].min().rename('cohort')
df = df.merge(user_cohort, on='user_id')
# 2. 월별 활동 집계
cohort_data = df.groupby(['cohort', 'order_month'])['user_id'].nunique().reset_index()
cohort_data.columns = ['cohort', 'order_month', 'active_users']
# 3. 경과 월 계산
cohort_data['months_since_first'] = (cohort_data['order_month'] - cohort_data['cohort']).apply(lambda x: x.n)
# 피벗 테이블 생성
cohort_pivot = cohort_data.pivot(
index='cohort',
columns='months_since_first',
values='active_users'
)
# 첫 달 기준 리텐션율 계산
cohort_retention = cohort_pivot.div(cohort_pivot[0], axis=0) * 100
# 히트맵
plt.figure(figsize=(14, 8))
sns.heatmap(
cohort_retention,
annot=True,
fmt='.1f',
cmap='YlGnBu',
cbar_kws={'label': '리텐션율 (%)'},
linewidths=0.5
)
plt.title('코호트별 월별 리텐션율', fontsize=16, fontweight='bold')
plt.xlabel('가입 후 경과 월', fontsize=12)
plt.ylabel('코호트 (가입 월)', fontsize=12)
plt.tight_layout()
plt.show()
# 인사이트
print("📊 리텐션 분석:")
print(f"- 1개월 후 평균 리텐션: {cohort_retention[1].mean():.1f}%")
print(f"- 3개월 후 평균 리텐션: {cohort_retention[3].mean():.1f}%")
print(f"- 6개월 후 평균 리텐션: {cohort_retention[6].mean():.1f}%")실행 결과
Error: 'cohort'
퀴즈 1: 월 × 요일 매출 히트맵
문제
2023년 데이터로 월별(1-12월)과 요일별 총 매출액을 히트맵으로 시각화하세요.
요구사항:
- 월을 행, 요일을 열로 배치
RdYlGn색상 팔레트 사용- 총계 행/열 추가 없이 기본 히트맵만
정답 보기
# 데이터 준비
df['month'] = df['created_at'].dt.month
df['day_of_week'] = df['created_at'].dt.dayofweek + 1
# 월 × 요일 매출 집계
monthly_daily = df.groupby(['month', 'day_of_week'])['sale_price'].sum().reset_index()
# 피벗 테이블
heatmap_data = monthly_daily.pivot(
index='month',
columns='day_of_week',
values='sale_price'
).fillna(0)
# 라벨 설정
month_labels = ['1월', '2월', '3월', '4월', '5월', '6월',
'7월', '8월', '9월', '10월', '11월', '12월']
day_labels = ['일', '월', '화', '수', '목', '금', '토']
heatmap_data.index = [month_labels[i-1] for i in heatmap_data.index]
heatmap_data.columns = [day_labels[i-1] for i in heatmap_data.columns]
# 히트맵
plt.figure(figsize=(12, 8))
sns.heatmap(heatmap_data, annot=True, fmt='.0f', cmap='RdYlGn',
cbar_kws={'label': '매출액 ($)'}, linewidths=0.5)
plt.title('월 × 요일별 매출 히트맵 (2023)', fontsize=16, fontweight='bold')
plt.xlabel('요일', fontsize=12)
plt.ylabel('월', fontsize=12)
plt.tight_layout()
plt.show()
print(f"📊 최고 매출: ${heatmap_data.max().max():,.0f}")
print(f"- 발생 월: {heatmap_data.max(axis=1).idxmax()}")
print(f"- 발생 요일: {heatmap_data.max().idxmax()}")실행 결과
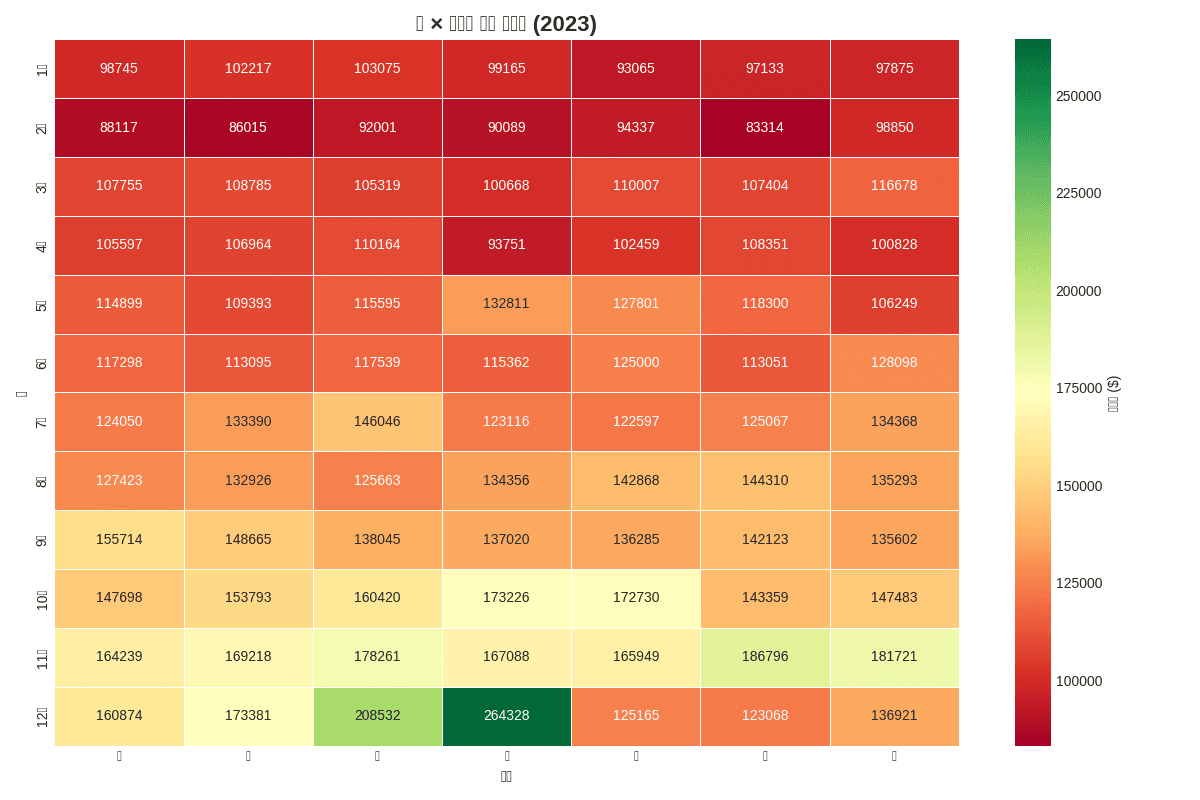
[Graph Saved: generated_plot_402a18d08b_0.png] 📊 최고 매출: $264,328 - 발생 월: 12월 - 발생 요일: 수
퀴즈 2: 상관관계 분석
문제
제품 데이터에서 다음 변수들의 상관관계를 분석하세요:
- retail_price (정가)
- cost (원가)
- sale_price (판매가)
- order_count (주문 건수)
하삼각 형태의 히트맵으로 시각화하세요.
정답 보기
# 제품별 통계 집계 (주문 건수 계산)
product_stats = df.groupby('product_id').agg({
'retail_price': 'mean',
'cost': 'mean',
'sale_price': 'mean',
'order_id': 'count'
}).rename(columns={'order_id': 'order_count'})
# 수치형 변수 선택
numeric_cols = ['retail_price', 'cost', 'sale_price', 'order_count']
corr_matrix = product_stats[numeric_cols].corr()
# 상삼각 마스크
mask = np.triu(np.ones_like(corr_matrix, dtype=bool))
# 히트맵
plt.figure(figsize=(8, 6))
sns.heatmap(
corr_matrix,
mask=mask,
annot=True,
fmt='.2f',
cmap='RdYlBu_r',
vmin=-1, vmax=1,
center=0,
square=True,
linewidths=0.5
)
plt.title('변수 간 상관관계 (하삼각)', fontsize=14, fontweight='bold')
plt.tight_layout()
plt.show()
# 해석
print("📊 상관관계 해석:")
print(f"- 정가-원가: {corr_matrix.loc['retail_price', 'cost']:.2f}")
print(f"- 정가-판매가: {corr_matrix.loc['retail_price', 'sale_price']:.2f}")
print(f"- 판매가-주문건수: {corr_matrix.loc['sale_price', 'order_count']:.2f}")실행 결과
Error: "['order_count'] not in index"
정리
색상 팔레트 가이드
| 용도 | 추천 팔레트 | 코드 |
|---|---|---|
| 순차형 (높을수록 진함) | Blues, YlOrRd | cmap='Blues' |
| 발산형 (양극단 강조) | RdYlGn, RdYlBu | cmap='RdYlGn' |
| 상관관계 | RdYlBu_r, coolwarm | cmap='RdYlBu_r' |
히트맵 활용 사례
| 분석 유형 | 행 | 열 | 값 |
|---|---|---|---|
| 시간 패턴 | 요일 | 시간 | 주문 건수 |
| 카테고리 매출 | 카테고리 | 월 | 매출 |
| 상관관계 | 변수 | 변수 | 상관계수 |
| 코호트 리텐션 | 가입 월 | 경과 월 | 리텐션율 |
다음 단계
히트맵을 마스터했습니다! 다음으로 트리맵에서 계층적 데이터 시각화를 배워보세요.
Last updated on